Performance & Runtime
Designed for low-latency, high-throughput inference with RadixAttention, prefix caching, and multi-GPU parallelism.
Models & Ecosystem
Broad support for Llama, Qwen, DeepSeek, and more. Compatible with Hugging
Face and OpenAI APIs.
Extensive Hardware Support
Native support across Hardware Platforms
including NVIDIA, AMD, Intel Xeon, Google TPU, and Ascend NPU accelerators.
Community & Training
Open-source with widespread adoption, powering 400k+ GPUs and integrated with major RL frameworks.
Get Started
SGLang is an inference framework meant for production level serving. It is designed to deliver low-latency and high-throughput inference across a wide range of setups, from a single GPU to large distributed clusters.Install SGLang
Install SGLang with pip, from source, or via Docker on your preferred hardware platform.
Quickstart
Launch your first model server and send requests in minutes with OpenAI-compatible APIs.
News and latest blogs

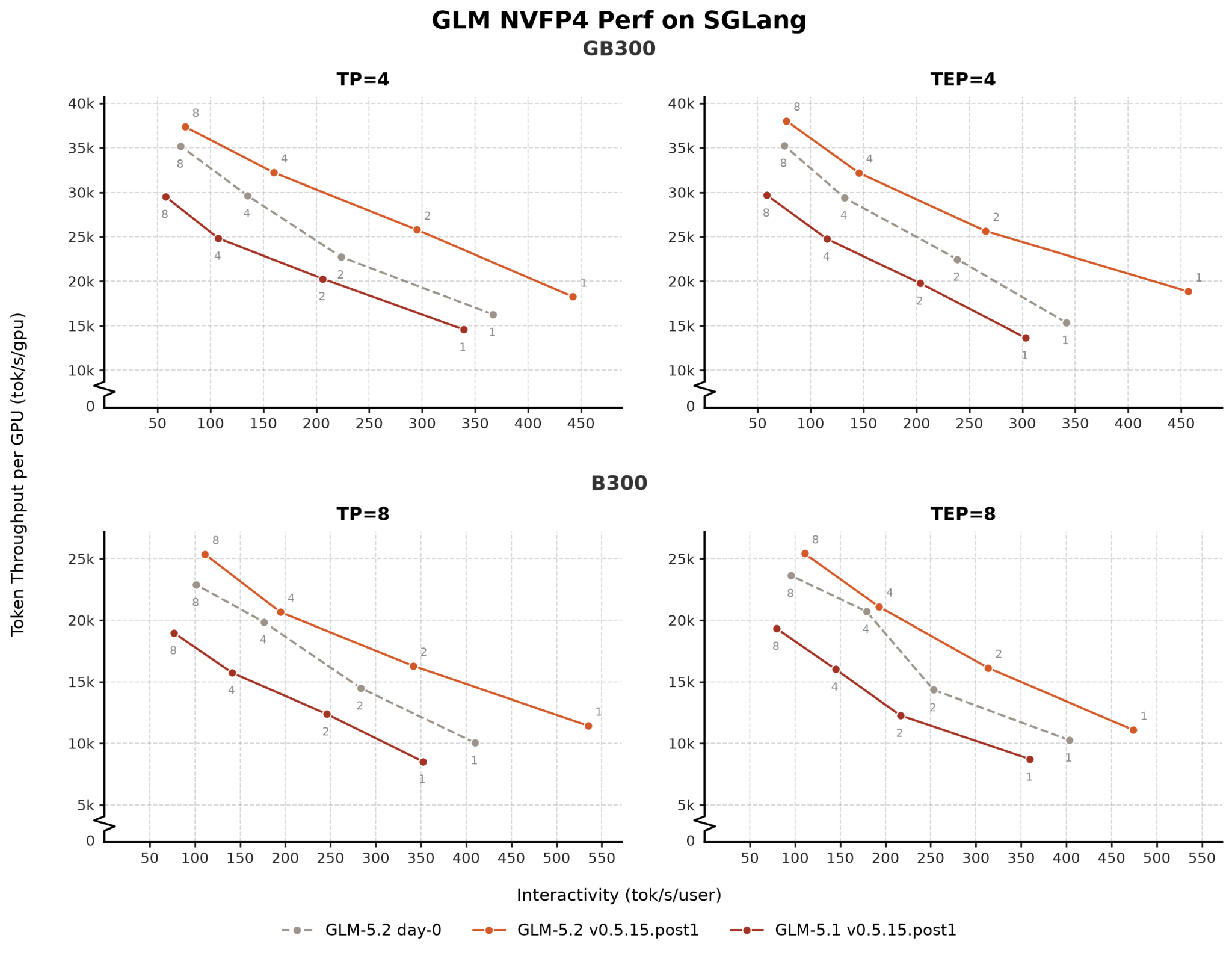
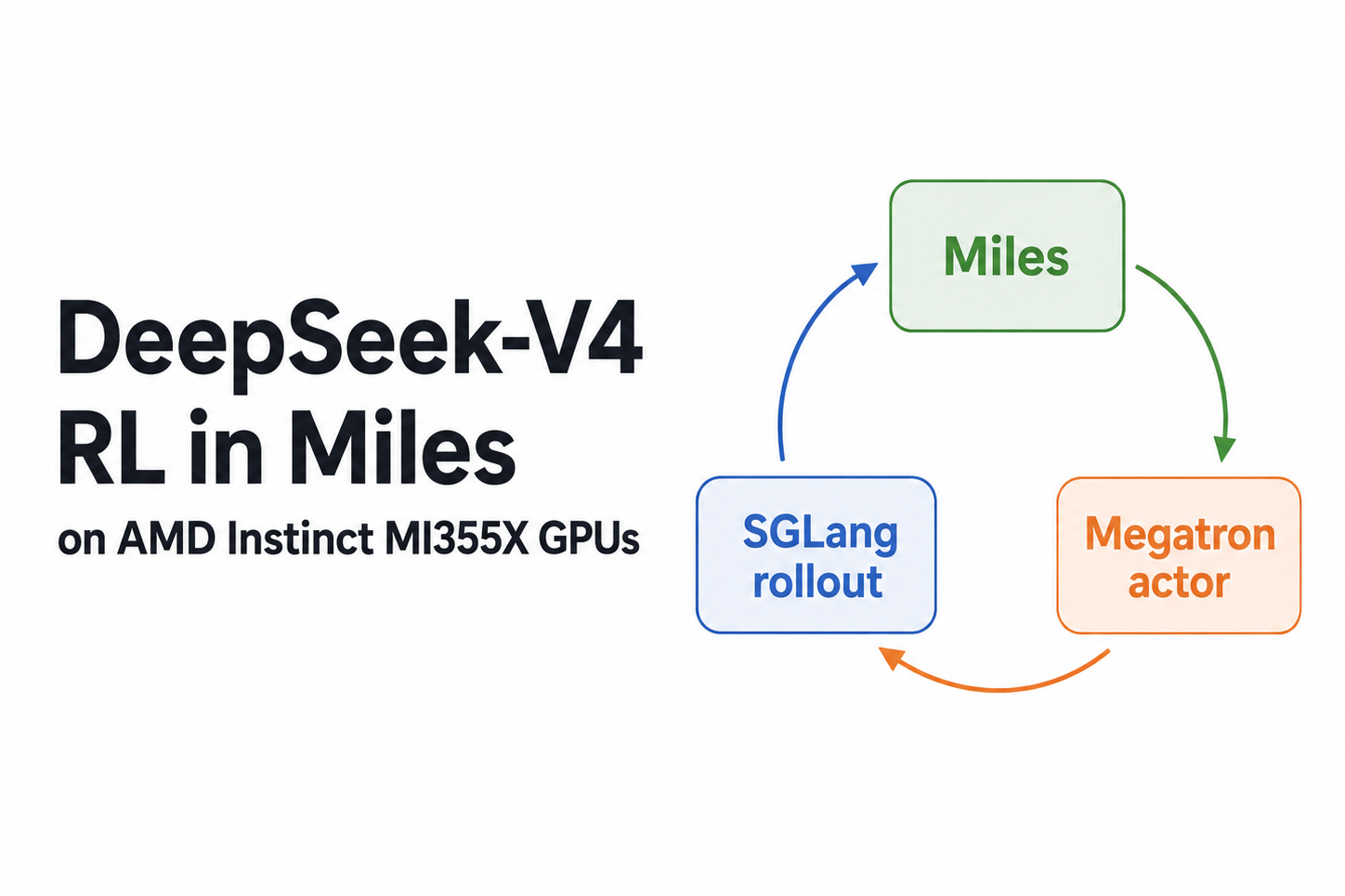
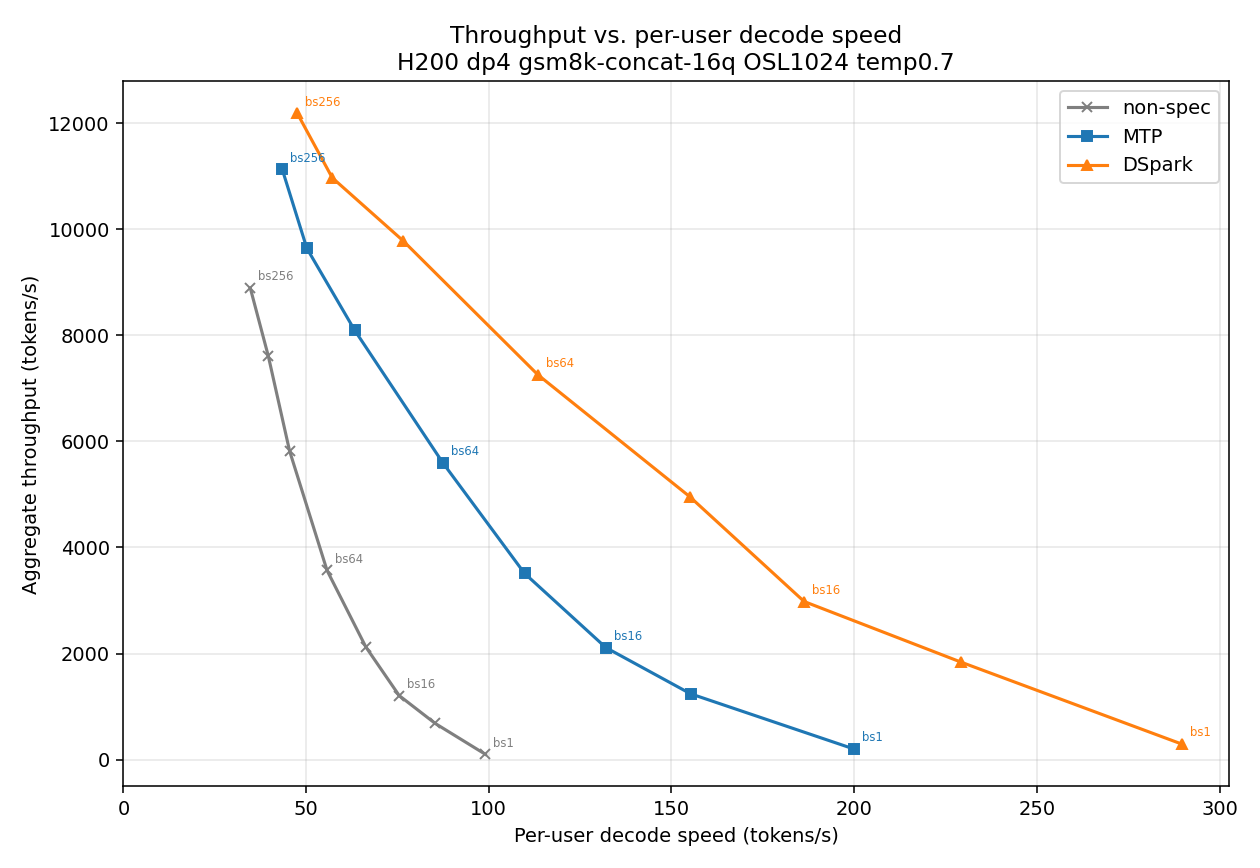

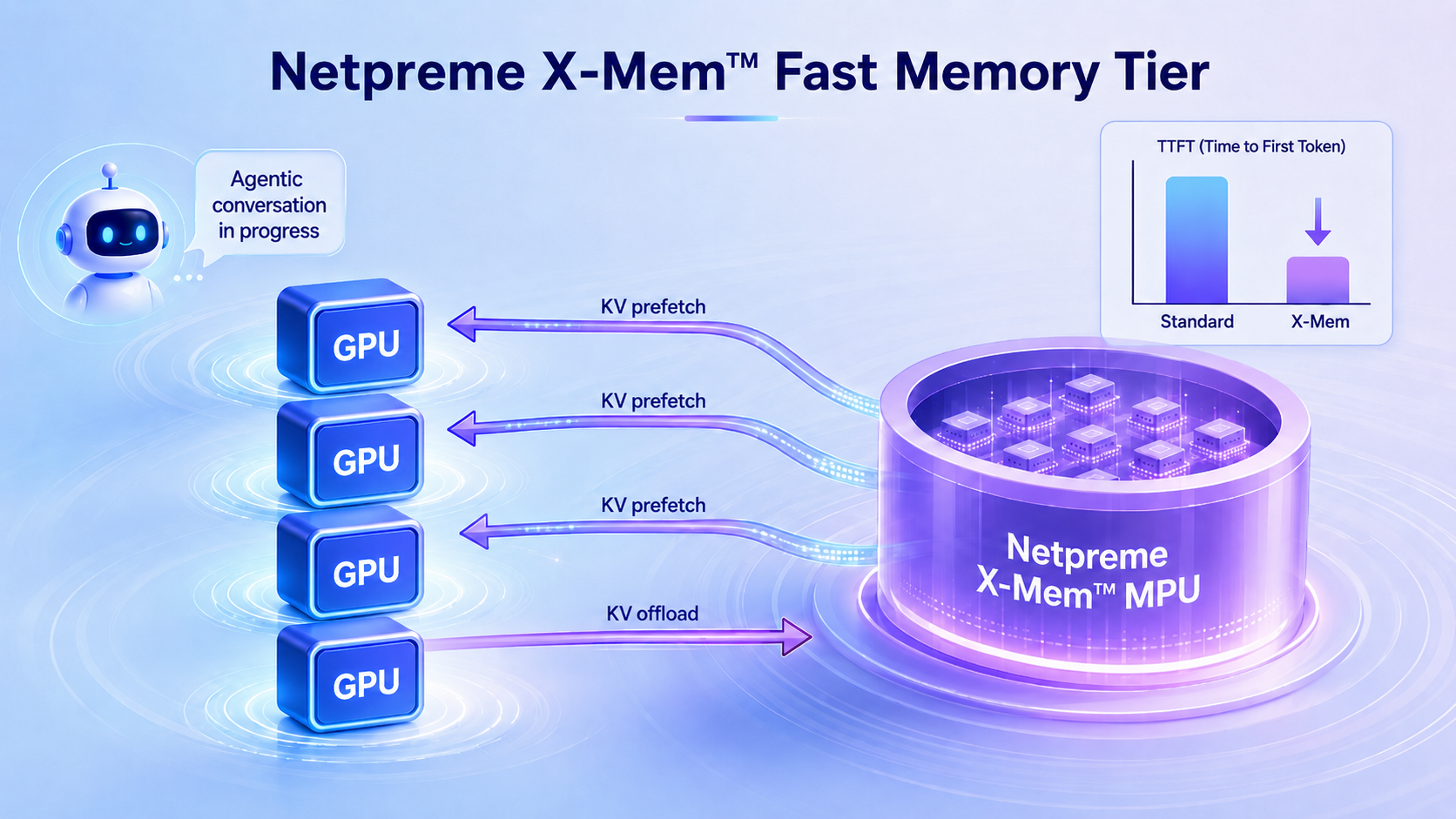
Learn more and join the community
Stay connected
Development roadmap to follow current priorities and upcoming work.
Weekly public development meeting to hear updates and join open discussions.
Slack for questions, feedback, and community support.
LMSYS blog for release notes, benchmarks, and technical deep dives.
Learning materials for blogs, slides, and videos.